Model Performance and Overfitting
Andreas Handel
2023-03-11 19:15:36.742676
Introduction
We discussed how to evaluate the performance of a model. We went through the idea of defining a single numerical value (cost function) and optimizing (usually minimizing) it to find the best model. There is however a very big caveat to this. The main point is: It usually doesn’t matter how well your model performs on the data that you used to build your model!
This is a very important point, and one that unfortunately a majority of scientific papers still get completely wrong! It is one area where modern machine learning is much more careful compared to the traditional way statistics is taught/used. In the machine learning field, it is very much recognized that it doesn’t matter a whole lot how well your model performs on the data that you used to build your model! What matters is performance on similar new data like the data that was used to fit the model.
I’m going to repeat this and similar sentences a bunch of times throughout the rest of the course 😁. If you only take away 2 main points from this course, this would be one if them. The other is that doing data analysis in a reproducible (automated) manner is critical.
So let’s go into some more details regarding this important point.
Should we really minimize the cost function?
We discussed that once we have chosen a cost function for our problem, we are trying to find a model that minimizes this cost function (e.g., minimizes the RMSE or the misclassification error), and models with smaller cost functions are better. The problem with this concept is that in general, a bigger model will be more flexible and thus able to fit the data better. However, when we do data analysis, we generally are not (only) interested in having a model that works well for the specific data sample we used to fit your model. Our main question/hypothesis usually does not concern the actual data we have/fit. Instead, we generally want to say something about ‘the larger world’.
If we are asking inferential questions, we are interested in what the data analysis teaches us about this system in general. E.g., if we analyze data to see if there is a correlation between levels of atmospheric pollutants and cases of asthma among our study population, we are usually really interested in knowing if such a correlation is real in general.
If we are asking predictive questions, we are interested in a model that can predict future observations, not the ones we already have. E.g., if we analyze data for a specific treatment, we are not very interested how well the model predicts the effect of the drug on the people for which we collected the data (we already know that). Instead, we want to make general predictions about the effectiveness of the treatment on future patients.
In either case, what we want is a model that is generalizeable (also sometimes called externally valid), and that applies equally well to new and similar data beyond the data we already collected.
What truly matters is how well our model can explain/predict other/future data, not just the data we are already observed!
If we build a very complex model in an effort to match our existing data as closely as possible, what generally happens is that our model overfits. That means it becomes very good at modeling the data we use to build the model, but it won’t generalize very well to the general, broader context of other/future data. The reason for that is that there is noise (random variability) in any dataset, and if we have a model that is too flexible, it will not only match the overall signal/pattern (if there is any) but will also capture all the noise in our sample, which leads to worse performance on future data that have different amounts and types of noise/variability.
Bias-variance trade-off
The general concept that models tend to fit the data that is used to build the model better as model complexity increases, but not perform so well on future/new data is also known as bias-variance trade-off.
Bias describes the fact that a model that is too simple might get the data “systematically wrong”. A more restricted model like a simple linear model usually has more bias. Another way of saying this is that the model underfits, i.e., there are still patterns in the data that the model does not capture. More complex models generally reduce the bias and the underfitting problem..
Variance describes how much a model would vary if it were fit to another, similar dataset. If a model goes close to the training data, it will likely produce a different fit if we re-fit it to a new dataset. Such a model is overfitting the data. More complex models tend to be more likely to overfit.
The following figure illustrates this concept. In this example, the data was produced by taking the black curve and adding some noise on top. This gives the data shown as circles. Three models are fit. A linear model (yellow) is too restrictive and misses important patterns. The next model (blue line) is more flexible and is able to capture the main patterns. The most complex model (green line) gets fairly close to the data. But you can tell that it is trying to get too close to the data and thus overfits. If we had another data sample (took the black line and added some noise on top), the green model would not do so well. This is shown on the right side, where the grey line plots the MSE for each model for the given dataset. As the model gets more complex/flexible, they get closer to the data, and the MSE goes down. However, what matters is the model performance on an independent dataset. This is shown with the red curve. Here, you can see that the blue model has the lowest MSE.
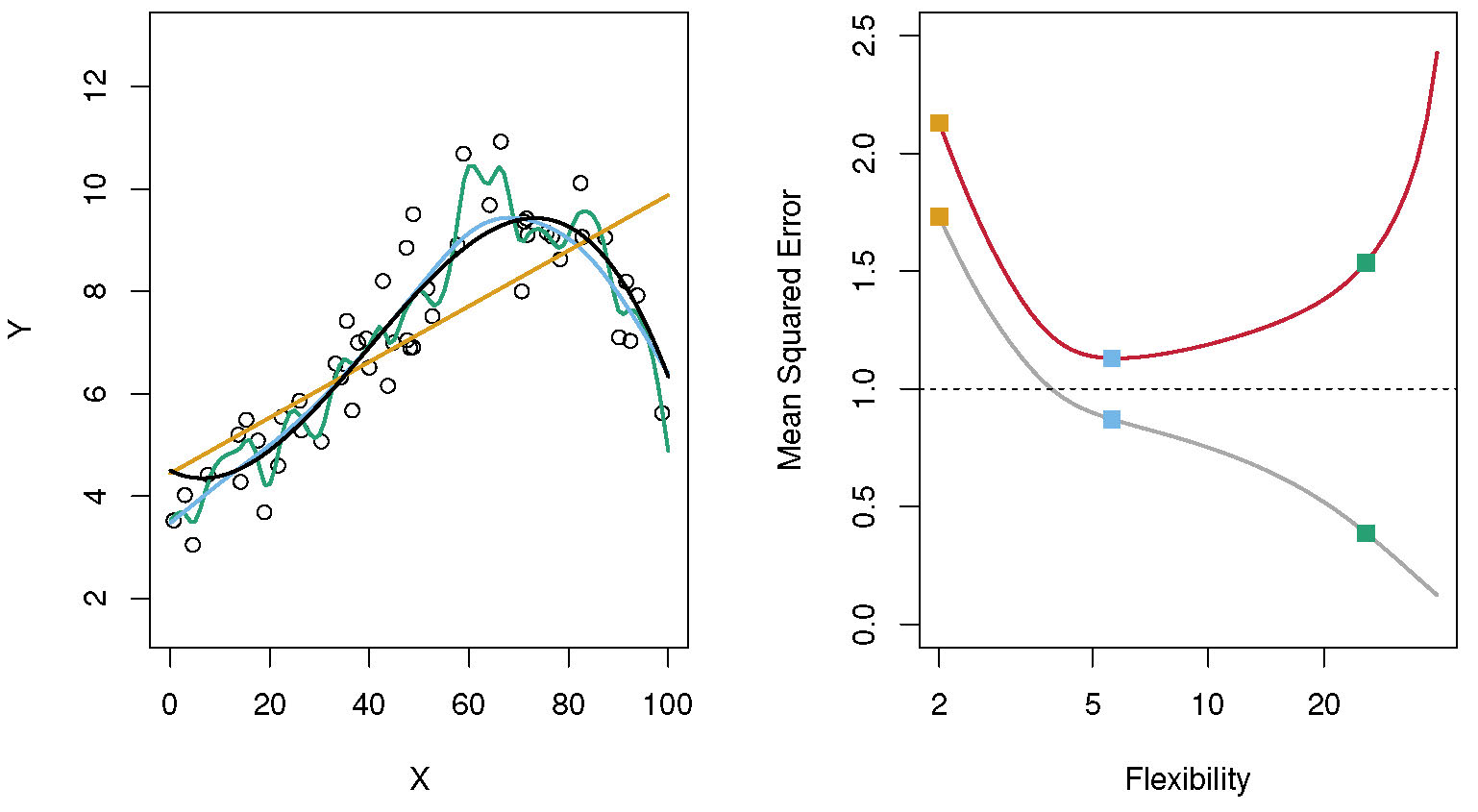
Bias-variance tradeoff. Source: ISLR.
The same concept holds for categorical outcomes, and for models with multiple predictors. No matter what the model, there is always a sweet spot for model complexity somewhere “in the middle”. This “middle” depends on the data and the question. Often, linear models are as good as one can get, and more complex models will overfit. Even for linear models, we might have to remove predictors to prevent overfitting (we’ll discuss that later). At other times, somewhat complicated models (e.g., neural nets) might perform best. In general, the more data (both quantity and richness), the less likely it is that a more complex model will lead to overfitting. However, we always need to check.
Overfitting and machine learning
If you only fit simple models (e.g., a linear model), and maybe decide based on scientific knowledge which predictors need to be in the model, then your risk of overfitting – while still present – is not that large. However, in machine learning, you often have complex models with many components that can be adjusted/tuned (we’ll get into that) to improve model performance. The danger is that if you have a very flexible model that can be finely tuned to perform well on the data, you have a very large risk of overfitting, namely of ending up with a model that is well tuned and performs very well on the data you use to build the model, but does not work so well on other data. Therefore, while overfitting is always something the be careful about, once you start using larger and more flexible models, you definitely need to guard against overfitting.
Dealing with overfitting
So now that you learned that the model that performs best (using whatever metric you chose) is not necessarily the best one, how can we evaluate model performance in a better way? There are different options.
More data: The ultimate test is, of course, to check your model on newly collected data. Or a completely independent dataset. However, collecting new data generally takes a lot of time and money, and often you might not have a completely independent dataset that measures the same variables as the one you are trying to analyze/fit. Therefore, for the remainder of the course, we assume that getting more data is not an option. (Though if you have that option, certainly go for it!)
Reserving some data: If you have enough data, you can perform an evaluation of model performance that tries to imitate the idea of evaluating the model on newly collected data. What you do is that right at the start of your analysis, you set some of your data aside and do not look at it until the very end! A common fraction of data that is set aside is 20%-40%, but there is no clear rule. This data you set aside is called your test/validation data. You need to completely ignore that data and are not allowed to use it while doing any statistical model fitting. You then take the rest of your data, referred to as training data, and do all your model building and fitting and model choosing, etc.
At the end and only once at the very end do you run your model on the test data and compute the performance. The way you do this is to give your model the input variables from the new data, ask the model to make predictions for the outcome, and use your metric/cost function to evaluate the performance of your model on that part of the data that your model has never seen before. This gives you an estimate of your model performance that is as honest as you can get without collecting new data. Be aware that even with this approach, you are likely still getting slightly better results than if you had evaluated your model on independently collected data (with somewhat different study design and data collection approaches). But in the absence of truly independent data, this is the best/most honest model performance evaluation you can do.
If you look at data analysis competitions such as Kaggle, this is how they operate. People need to submit their model predictions, and the model will be evaluated on a final dataset, only once, at the end of the competition. And whoever scores highest on that dataset wins, no matter how well they did on the leaderboard.
While such a train/test split is an excellent thing to do, there are some constraints. First, you need to have enough data. If your dataset is small (<100-1000 observations, depending on the number of predictors and model complexity), then this approach will make you give away data that you need to build your model, and won’t provide robust insights. Second, you still need a way to decide which model to chose as your final model, and as mentioned above, using the one with the smallest cost function as evaluated on the data that was used to build the model is not good. Thus, you still need to figure out how to evaluate which model is best during the model building process. To that end, an approach called cross-validation has become very widely used and is currently - in my opinion - the best method to evaluate and choose your model.
To do the train/test split in R, you can use the rsample package
which is part of tidymodels.
Cross-validation during model building: Cross-validation (CV) is a reasonably straightforward approach. It mimics the train/test idea just described, but is now applied during the model fitting process. The idea is that you take the data you set aside for the model building process (i.e., your training data), and during the model building procedure, you repeatedly split your data into a portion to which you fit our model, and a portion which you use to evaluate model performance. You repeat this many times to get several samples and always use some portion of the data to fit the model, and the remaining part to evaluate it.
You might not be surprised to learn that this is another place where terminology is confusing and inconsistent. The words training data and test/validation data are used both for the initial split described above, and the split done in the CV procedure. A recent suggestion by Max Kuhn is to call the splits done by CV the analysis and assessment portions of the data. This terminology and a nice schematic is for instance shown here. I will try to use that terminology, but I might not be consistent. And other materials you see/read certainly do not follow that terminology, as you will see already below.
There are different ways to do the data splitting during cross-validation. A common setup is to randomly divide the data set into k blocks (called folds). You then use the data in all but one of the blocks to fit the model, then compute the cost function/performance metric (e.g., the RMSE) using the remaining block. You repeat that for all k blocks. The average value of the model performance over the k blocks is the target that you want to optimize. One usually chooses k = 5 or 10 blocks/folds, which has shown in simulation studies to give the best variance-bias trade-off. The figure shows an example of a 4-fold cross-validation for a categorical outcome (color of the balls). Note that this figure uses the train/test terminology for labeling the blocks, not the analysis/assessment terminology.
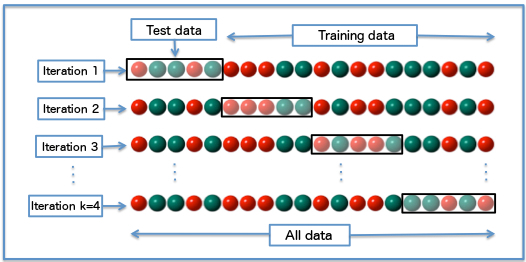
In addition to the standard way of splitting the data, there are different sampling variants. For instance, if you have longitudinal data, or otherwise data with structure, you might want to sample in a different way (e.g., sample the earlier times and predict later times). One variant of the cross-validation approach is the leave-one-out (LOO) cross-validation, which removes each data point one at a time as the test data and therefore performs the train/test part N times. You will also often see repeated cross-validation, which just adds another round of sampling on top to get better distributions (e.g., a 10-fold CV 10 times repeated gives 100 samples, which will be used to compute model performance).
Cross-validation works for most situations and is quite robust. It is
also fairly easy to implement. In R, the tidymodels
framework allows for easy CV, and we’ll make use of that. Thus CV is a
good default strategy. However, sometimes it is not possible or
desirable to use CV. Occasionally, datasets are so small that you need
all the data just to fit your model. More commonly, your data are too
large and/or your model too complex to make CV run in a reasonable
amount if computational time. (Often, one can speed up things by
down-sampling the data, using faster algorithms, or running code in
parallel on a computer cluster.)
Other ways to minimize overfitting
Model selection criteria: Are an alternative option if CV is not possible/wanted. Information criteria, such as AIC, BIC, DIC and similar, compute a measure that is a trade-off between good fit to the data (low-cost function/high performance) and model complexity (number of parameters). Approaches based on such selection criteria essentially try to guess how the model would perform if it were to be fit to new data, without actually trying to do it (in contrast to CV). The disadvantage is that these guesses as to how the model might perform on new data are not as reliable as actually evaluating model performance on such data through CV. The advantage is that no sampling is needed, which means these approaches are much less computationally intensive. For all those approaches (AIC, BIC, etc.), things are set up that a model with a smaller value is considered better. These measures - thankfully! - do not have the arbitrary p<0.05 value cut-off common in frequentist statistics. For AIC, a rule of thumb is that a difference of 10 between 2 models is meaningful. (Unfortunately, people seem to not be able to make their own decisions and need crutches, so arbitrary cut-offs for AIC/BIC/etc. have started to show up in the literature.)
There is a lot of math behind information criteria (AIC and similar),
see the book Model Selection
and Multimodel Inference. Fortunately, one does not need to know the
mathematical details to use those measures, just common sense. A lot of
statistical methods in R can report such selection criteria and the
broom package of tidymodels can often be used
to further
process such reported outcomes.
Regularization: If one fits models in a Bayesian framework, one needs to supplies priors for each parameter. If one provides informative priors that constrain the possible values of the model parameters based on prior scientific information, it leads to what is called regularization and generally reduces overfitting. In a frequentist approach, there are methods such as LASSO which introduce a extra terms in the performance metric to try to prevent overfitting.
Model fitting done the right way
To repeat (again): We generally want to know how well a model performs in general and on new data - not the sample we fit it to. Testing/reporting model performance for the data the model was fit to very often leads to overfitting and optimistic/wrong conclusions about new/future data. To minimize overfitting, here is my recommended strategy (I’m sure it’s not the only one, so what matters most is that you clearly think about what each step in your analysis means/implies):
- If you have enough data and care about predictive performance, set some data aside for a final validation/test. If you don’t have a lot of data, you might need to skip this split.
- If you choose to use all your data for model fitting purposes, and don’t evaluate your model on data not used during model building/training, you need to interpret your findings as exploratory and hypothesis generating, and you need to be careful about trying to draw generalizable conclusions.
- If you have enough data (>100s observations) and CPU power, use cross-validation (CV) approaches to determine the best model. If for some reason (mainly computational time or small data) CV is not feasible, use AIC & Co.
- Think carefully about your cost function/metric! A model that is great at predicting the wrong outcome is useless! (See e.g., the brain cancer example.)
- No matter what approach you use, choosing a model based on performance alone is not enough. Perform additional evaluations (see next units).
Further comments
Don’t forget: Performance is not everything. Even if you have a model that performs best on the independent/cross-validated data, you might want to opt for a “worse” model that is easier to interpret and potentially use. Having smaller and simpler models can sometimes be of little importance and other times of great importance.
For instance, if you want to build a model that allows doctors to predict the chance that a patient has a certain disease, you might want to have a model that only uses the fewest (or easiest/cheapest to measure) variables to obtain good performance. So if you collect a lot of data, some based on checking patient symptoms and some on lab results, you might not want to use all those variables in your model. Let’s say that you had data on 10 predictors, 5 for easy to measure symptom variables (e.g., body temperature and similar), and 5 variables that come from different lab tests. You’ll evalute models with different predictors (performing e.g., subset selection or LASSO, which we’ll discuss soon) and find that the best performing model retains 3 symptom variables and 2 lab tests. Let’s say its performance is 95% (I’m purposefully fuzzy about what that performance exactly is since it doesn’t matter. It could be accuracy, or F1 score, or AUC, or…). But you also find that another model that contains 4 symptom variables and no lab tests has 85% performance. Which do you choose? That comes back to our discussion about assessing model quality: Performance is an important measure, but it’s not the only one. In this case, since you could get data on the 4 symptoms very quickly and cheaply, you might want to recommend that model for most doctors offices, and only use the better, but more time-consuming and expensive model with the 2 lab tests in settings such as high-risk populations in the hospital.
In contrast, if you are a bank that tries to predict fraud by having complicated models that constantly analyze various data streams, you might not care how complicated and big your model is, only that the performance in flagging fraudulent transactions is as good as possible.
Further learning
This blog post provides a nice further discussion of the idea of generalization and how different areas of data science (statistics, machine learning, causal modeling) think about this problem. I think the most important paragraph is actually the short last one. I want to add to this that while different areas might think about the question of generalization differently, all of them more or less agree, that in the end, what is important is the general conclusions you can draw from your statistical modeling analysis and it doesn’t matter (by itself) how well your model performs on the data that you used to build your model! What matters is what it means more generally.
In this blog post, Frank Harrell discusses some of the potential caveats for using methods such as cross-validation.
Parts of chapter 2 of HMLR cover similar ground to what I discussed above. You might want to give it a read-through. Some of the topics that are discussed in that overview chapter are topics we’ll cover later. Similarly chapters 2 and 5 of ISL also covers some of these topics, e.g. the bias-variance trade-off. You looked at some of that material previously, revisiting might be worth it.
Chapters 11 and 12 of the
tidymodels with R book provide additional discussion of
the sampling/CV approaches. Another discussion of CV is chapter 30
of IDS.
Take a look at these and other sources and work through any that you find most helpful.