Processing Data
Overview
This unit provides a brief introduction to the topic of data processing.
Learning Objectives
- Be familiar with the topic of data processing
- Understand the importance of proper processing for data analysis
Introduction
I want to remind you of this diagram:
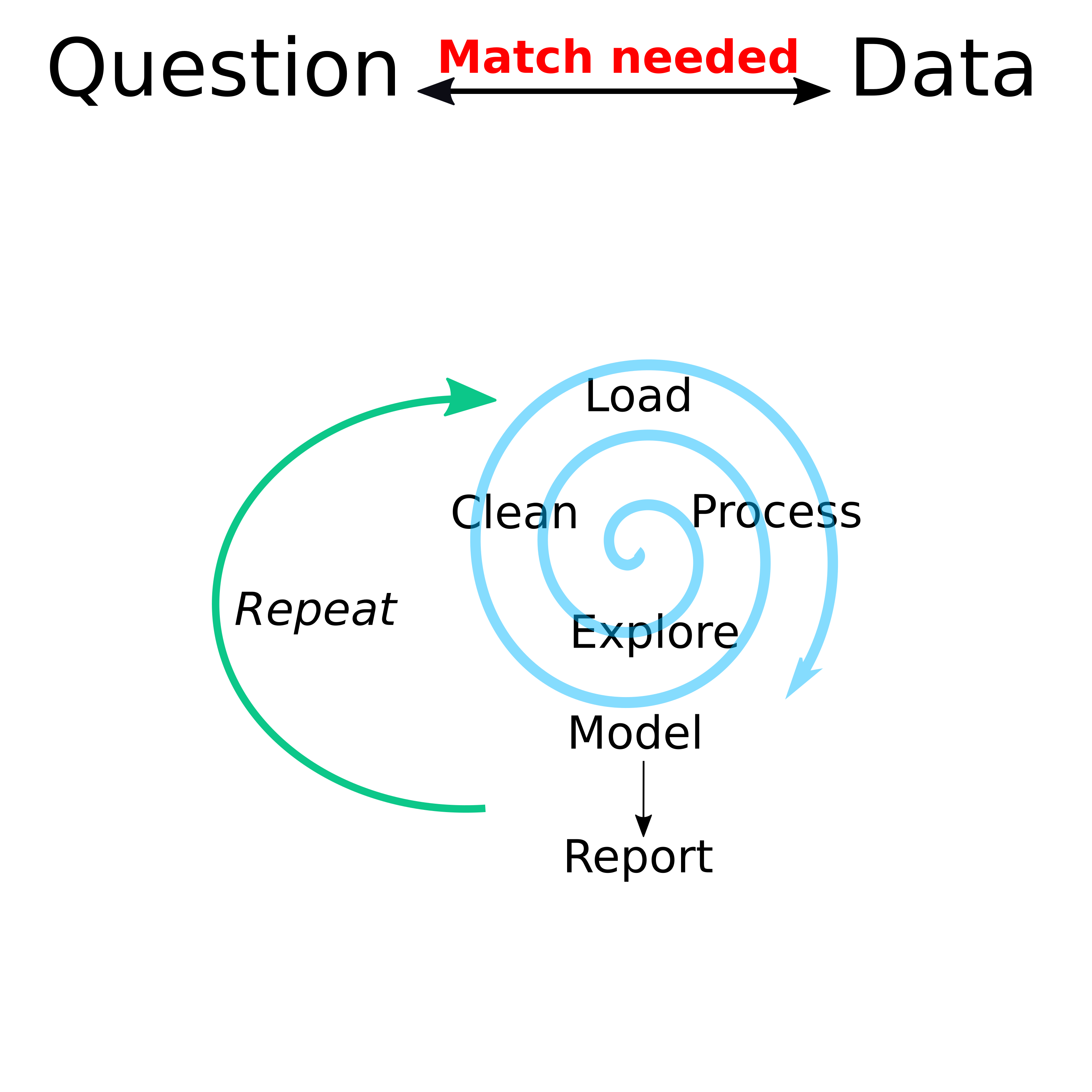
Different data-analysis related tasks rarely happen in a linear sequence. Instead there is a general stage before statistical analysis where you mess with your data (that’s a technical term 😁) to get ready for the main formal analysis. And often, as you start that formal analysis, you’ll have to go back and do some more cleaning/exploration.
While one can distinguish the different tasks of Cleaning, Exploring and Processing, one can also more generally think of them as all being a part of data processing. Alternative terms often used instead of processing are data wrangling or tidying. Cleaning, munging.
As with any part of the data analysis process, processing should be automated, reproducible, and well-documented. No “fixing by hand”!
Data processing tasks
Almost all datasets require some processing before they are in a format that can be used with statistical models. For any data analysis, the majority of time is likely spent in the data processing and exploration steps before the main model fitting. Some folks suggest that this processing part is as much as 80% of the time spent on the whole project. In my experience, this is about right.
While every dataset is different, there are certain tasks that are common. Those involve missing data, recoding variables, and dealing with outliers. Further ones are merging and reshaping of the data. We will discuss some of them in further units.
Data processing and exploratory data analysis (EDA)
As you process your data, you need to explore your data to figure out what needs processing. As such, exploratory data analysis (EDA) and data processing generally go together.
EDA generally relies on making figures and tables, and we’ll talk about that in a separate module. There is no clear definition for exploratory analysis. Beyond figures and tables, it can sometimes involve simple statistical computations, for instance you might compute correlations among predictors.
You can think of EDA as any process that happens before you start building and fitting your main models. Again, it often happens concurrently with the processing of the data.
Summary
Data processing is a major and crucial part of any data analysis project. It can be tedious, but with practice and good tools, you might even reach a point where you enjoy the process somewhat 😁.
Further resources
Chapters 4 and 5 of The Art of Data science (ADS) discuss some processing and exploration tasks and examples. if you want to work along, see the Some practice section of the Data Analysis Overview page for some details on how to do it.
The whole R4DS book focuses on the early stages of data analysis, including processing and exploration. Definitely keep checking this book if you are looking for more information on a specific topic.